Contents
Contents
Queues
Queues only apply to Asynchronous Service Operations. A queue defines several key aspects of how the publishing and subscribing of the messages in the queue are handled.
- You can pause a queue and all work will stop. This includes publishing and subscribing. This can be very useful during maintenance or when receiving systems are undergoing maintenance.
- A queue can contain many service operations. You generally group service operations into the same when they are related or you need those events to process in some order.
- You can mark a queue to process in an unordered status. I don’t find this is often used but it is an option.
A good example of when several service operations are in the same queue that need to process in order are the “person” related service operations in the PERSON_DATA queue.
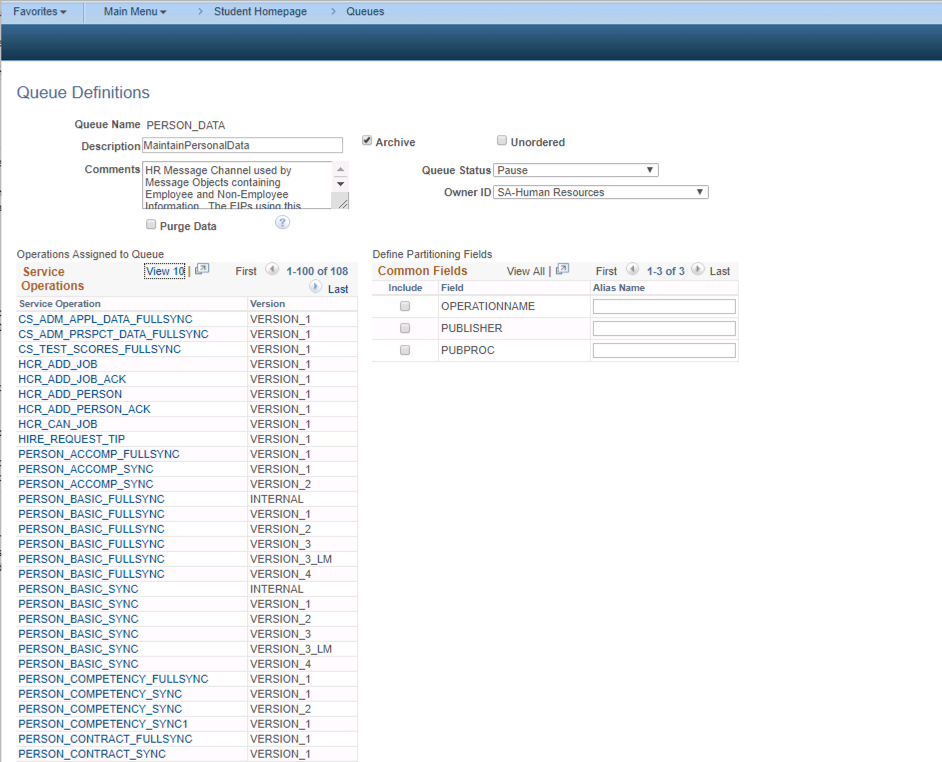
The default way this is configures is there is NOT partitioning. So events will be processed and published in the order they are received. This make some sense. I would argue the default configuration for this queue should probably be partitioned by EMPLID. With the standard setup of this queue a subscribing system will receive the messages in the order they were published. So let’s look at this sequence of events:
- Person Created and save(PERSON_BASIC_SYNC with “Created” Meta Data)
- Person Updated with new Email Address (PERSON_BASIC_SYNC with “add email” Meta Data)
- Person Updated with typo in Email Address (PERSON_BASIC_SYNC with “update email” Meta Data)
- Person Visa data updated (PERSON_VISA_CITIZEN_SYNC)
- Person Diversity data updated (PERSON_DIVERSITY_SYNC)
If you have these events happening in an HCM instance and they need to publish to something like a Campus system you need these events to be sent in the order they are created. The create of the person needs to happen and be processed first in the receiving system so the person can be created in that system. Then the later updates can be processed. You can’t process the PERSON_DIVERSITY_SYNC prior to the EMPLID being created. If you processed the “update email” before the “add emails” the receiving system would have unreliable results.
Queue Partitioning
This section will explain Queue partitioning. Partitioning is defined at the Queue level and it tells the integration broker if messages in a queue can be processed in parallel or not. This is queue dependent and setting up proper queues and partitioning can be critical in setting up effective loosely coupled systems. If you configure it incorrectly, one error in the queue can block everything which can be disastrous for high volume message queues. There are times that you want to configure partitioning and other times when you do not. This is really dependent on the nature of the message and how the receiving system handles the data.
When a queue is partitioned, that means that the messages can be processed in parallel. Any messages with the same “common fields” will process in the order they were received. Partitioning is best explained with an example.
USER_PROFILE Queue Partitioning Example
Lets take the case of the USER_PROFILE_SYNC service operation. This Service Operation is used to sync PeopleTools user profiles between different PeopleTools databases or other systems. This service operation is defined in the USER_PROFILE queue.
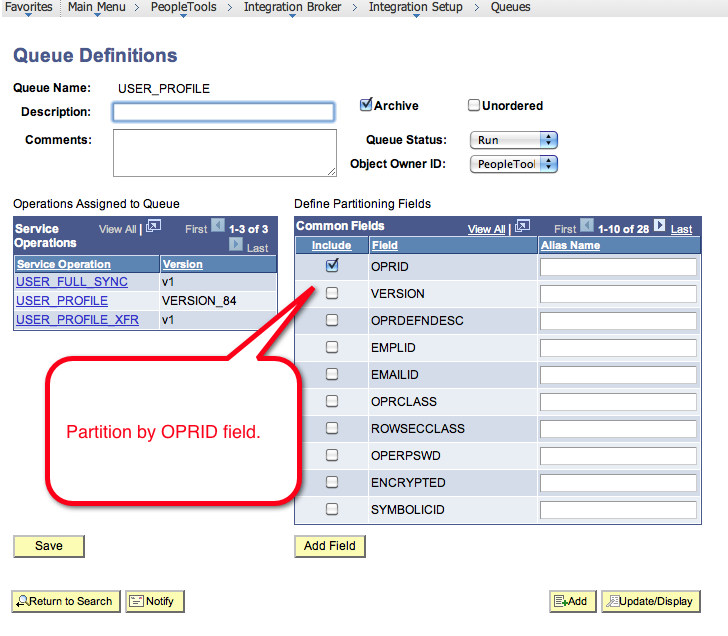
When you look at the queue setup for the USER_PROFILE queue you can see that all the common fields are listed on the right hand side. In this screenshot the OPRID is checked for partitioning.
- Lets say that 3 users all change their password in your HR database and the USER_PROFILE_SYNC service operation fires to synchronize that user change with your Finance Database.
- Let’s assume that user JOHND, SALLIES, and ROBERTD all changed their password in that order but within seconds of each other. The user JOHND hit save first so the USER_PROFILE_SYNC message for his user profile was queued up for publication to your finance database.
- Let’s say that that the JOHND user id did not have permission to publish user profile messages to finance due to a security setup on his profile.
Since we have partitioning setup on the OPRID common field level, the publication error on the JOHND user profile will NOT block the publication messages of SALLIES and ROBERTD. The SALLIES and ROBERTD message both went to success. This is shown in the drawing where each user basically has their own “lane” in the queue and the “lane” is setup based on the partitioned field.
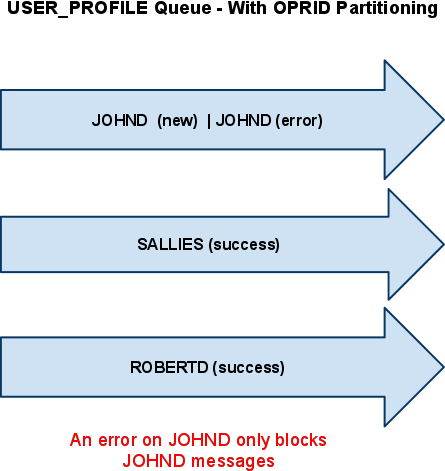
If JOHND decides that he does not like his new password and changes it a minute later then that second password change will actually sit in “NEW” status behind the message in error because the queue is partitioned and the integration broker was smart enough to realize that there was a message for that user in error and it does not processes the second or third message. All messages for the JOHND user are basically frozen but other user profiles are not impacted. If someone were to come in and cancel the JOHND message in error then the message behind it would process. However, it could lead to unpredictable results
Chris Malek
Chris Malek is a PeopleTools® Technical Consultant with over two decades of experience. He is available for consulting engagements.
Work with ChrisSubscribe to Updates
PeopleSoft Simple Web Services
SWS turns SQL into production REST APIs — ready for AI, modern apps, and partner integrations. One install, unlimited potential.
- Configuration-driven, no coding required
- JSON, XML, and CSV output
- Works across all PeopleSoft pillars
- Built on 25+ years of PeopleSoft expertise
PeopleSoft Simple Web Services
A powerful PeopleSoft bolt-on that makes REST web services easy. You bring the SQL, SWS handles the rest.
- Go from idea to production in minutes
- Zero code migrations after install
- JSON, XML, and CSV output supported
- No PeopleCode or Integration Broker expertise required
PeopleSoft Simple Web Services
Traditional PeopleSoft web services cost $3,600–$13,000 each to develop. SWS deploys production REST APIs in under 5 minutes through configuration alone.
- No PeopleCode or Integration Broker expertise required
- Works across Campus Solutions, HCM, and Financials
- Built-in pagination, caching, and nested data structures
- Trusted by institutions across higher education and government
PeopleSoft Simple Web Services
Turn PeopleSoft data into clean REST APIs for AI integrations, modern applications, and vendor data feeds. Configuration-driven — no PeopleCode required.
- Deploy production APIs in under 5 minutes
- AI and LLM ready (RAG, chatbots, intelligent search)
- JSON, XML, and CSV output
- Zero modifications to delivered PeopleSoft objects
psLens Operations & Intelligence
Look up any record, field, page, or component, audit security, and monitor Integration Broker across every database — in seconds.
- 30+ object types browsable
- 16 real-time alert types
- Read-only by design
- No App Designer or SQL required
psLens Operations & Intelligence
A web console built for the PeopleSoft community — operational monitoring, security auditing, and metadata browsing in one tool.
- Sub-second object search
- Catch stuck IB messages before users do
- Audit service permissions from one screen
- Works in any browser
psLens Operations & Intelligence
On-demand security and operational reports for your PeopleSoft environment — no client install required.
- 14 on-demand reports
- Markdown export for AI/LLM workflows
- No shared tenancy
- Built on 25+ years of PeopleSoft expertise
psLens Operations & Intelligence
Research any PeopleSoft object and monitor system health from a single browser tab — no App Designer, no SQL.
- 30+ PeopleSoft object types browsable
- Real-time alerts before users report problems
- Read-only and secure
- Private alpha — early access now